Step 1: Write your hypotheses and plan your research design
To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design.
Writing statistical hypotheses
The goal of research is often to investigate a relationship between variables within a population. You start with a prediction, and use statistical analysis to test that prediction.
A statistical hypothesis is a formal way of writing a prediction about a population. Every research prediction is rephrased into null and alternative hypotheses that can be tested using sample data.
While the null hypothesis always predicts no effect or no relationship between variables, the alternative hypothesis states your research prediction of an effect or relationship.
- Null hypothesis: A 5-minute meditation exercise will have no effect on math test scores in teenagers.
- Alternative hypothesis: A 5-minute meditation exercise will improve math test scores in teenagers.
- Null hypothesis: Parental income and GPA have no relationship with each other in college students.
- Alternative hypothesis: Parental income and GPA are positively correlated in college students.
Planning your research design
A research design is your overall strategy for data collection and analysis. It determines the statistical tests you can use to test your hypothesis later on.
First, decide whether your research will use a descriptive, correlational, or experimental design. Experiments directly influence variables, whereas descriptive and correlational studies only measure variables.
- In an experimental design, you can assess a cause-and-effect relationship (e.g., the effect of meditation on test scores) using statistical tests of comparison or regression.
- In a correlational design, you can explore relationships between variables (e.g., parental income and GPA) without any assumption of causality using correlation coefficients and significance tests.
- In a descriptive design, you can study the characteristics of a population or phenomenon (e.g., the prevalence of anxiety in U.S. college students) using statistical tests to draw inferences from sample data.
Your research design also concerns whether you’ll compare participants at the group level or individual level, or both.
- In a between-subjects design, you compare the group-level outcomes of participants who have been exposed to different treatments (e.g., those who performed a meditation exercise vs those who didn’t).
- In a within-subjects design, you compare repeated measures from participants who have participated in all treatments of a study (e.g., scores from before and after performing a meditation exercise).
- In a mixed (factorial) design, one variable is altered between subjects and another is altered within subjects (e.g., pretest and posttest scores from participants who either did or didn’t do a meditation exercise).
First, you’ll take baseline test scores from participants. Then, your participants will undergo a 5-minute meditation exercise. Finally, you’ll record participants’ scores from a second math test.
In this experiment, the independent variable is the 5-minute meditation exercise, and the dependent variable is the math test score from before and after the intervention.
Measuring variables
When planning a research design, you should operationalize your variables and decide exactly how you will measure them.
For statistical analysis, it’s important to consider the level of measurement of your variables, which tells you what kind of data they contain:
- Categorical data represents groupings. These may be nominal (e.g., gender) or ordinal (e.g. level of language ability).
- Quantitative data represents amounts. These may be on an interval scale (e.g. test score) or a ratio scale (e.g. age).
Many variables can be measured at different levels of precision. For example, age data can be quantitative (8 years old) or categorical (young). If a variable is coded numerically (e.g., level of agreement from 1–5), it doesn’t automatically mean that it’s quantitative instead of categorical.
Identifying the measurement level is important for choosing appropriate statistics and hypothesis tests. For example, you can calculate a mean score with quantitative data, but not with categorical data.
In a research study, along with measures of your variables of interest, you’ll often collect data on relevant participant characteristics.
| Variable | Type of data |
|---|---|
| Age | Quantitative (ratio) |
| Gender | Categorical (nominal) |
| Race or ethnicity | Categorical (nominal) |
| Baseline test scores | Quantitative (interval) |
| Final test scores | Quantitative (interval) |
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Grammar
- Style consistency

Step 2: Collect data from a sample
In most cases, it’s too difficult or expensive to collect data from every member of the population you’re interested in studying. Instead, you’ll collect data from a sample.
Statistical analysis allows you to apply your findings beyond your own sample as long as you use appropriate sampling procedures. You should aim for a sample that is representative of the population.
Sampling for statistical analysis
There are two main approaches to selecting a sample.
- Probability sampling: every member of the population has a chance of being selected for the study through random selection.
- Non-probability sampling: some members of the population are more likely than others to be selected for the study because of criteria such as convenience or voluntary self-selection.
In theory, for highly generalizable findings, you should use a probability sampling method. Random selection reduces several types of research bias, like sampling bias, and ensures that data from your sample is actually typical of the population. Parametric tests can be used to make strong statistical inferences when data are collected using probability sampling.
But in practice, it’s rarely possible to gather the ideal sample. While non-probability samples are more likely to at risk for biases like self-selection bias, they are much easier to recruit and collect data from. Non-parametric tests are more appropriate for non-probability samples, but they result in weaker inferences about the population.
If you want to use parametric tests for non-probability samples, you have to make the case that:
- your sample is representative of the population you’re generalizing your findings to.
- your sample lacks systematic bias.
Keep in mind that external validity means that you can only generalize your conclusions to others who share the characteristics of your sample. For instance, results from Western, Educated, Industrialized, Rich and Democratic samples (e.g., college students in the US) aren’t automatically applicable to all non-WEIRD populations.
If you apply parametric tests to data from non-probability samples, be sure to elaborate on the limitations of how far your results can be generalized in your discussion section.
Create an appropriate sampling procedure
Based on the resources available for your research, decide on how you’ll recruit participants.
- Will you have resources to advertise your study widely, including outside of your university setting?
- Will you have the means to recruit a diverse sample that represents a broad population?
- Do you have time to contact and follow up with members of hard-to-reach groups?
Your participants are self-selected by their schools. Although you’re using a non-probability sample, you aim for a diverse and representative sample.
Calculate sufficient sample size
Before recruiting participants, decide on your sample size either by looking at other studies in your field or using statistics. A sample that’s too small may be unrepresentative of the sample, while a sample that’s too large will be more costly than necessary.
There are many sample size calculators online. Different formulas are used depending on whether you have subgroups or how rigorous your study should be (e.g., in clinical research). As a rule of thumb, a minimum of 30 units or more per subgroup is necessary.
To use these calculators, you have to understand and input these key components:
- Significance level (alpha): the risk of rejecting a true null hypothesis that you are willing to take, usually set at 5%.
- Statistical power: the probability of your study detecting an effect of a certain size if there is one, usually 80% or higher.
- Expected effect size: a standardized indication of how large the expected result of your study will be, usually based on other similar studies.
- Population standard deviation: an estimate of the population parameter based on a previous study or a pilot study of your own.
Step 3: Summarize your data with descriptive statistics
Once you’ve collected all of your data, you can inspect them and calculate descriptive statistics that summarize them.
Inspect your data
There are various ways to inspect your data, including the following:
- Organizing data from each variable in frequency distribution tables.
- Displaying data from a key variable in a bar chart to view the distribution of responses.
- Visualizing the relationship between two variables using a scatter plot.
By visualizing your data in tables and graphs, you can assess whether your data follow a skewed or normal distribution and whether there are any outliers or missing data.
A normal distribution means that your data are symmetrically distributed around a center where most values lie, with the values tapering off at the tail ends.
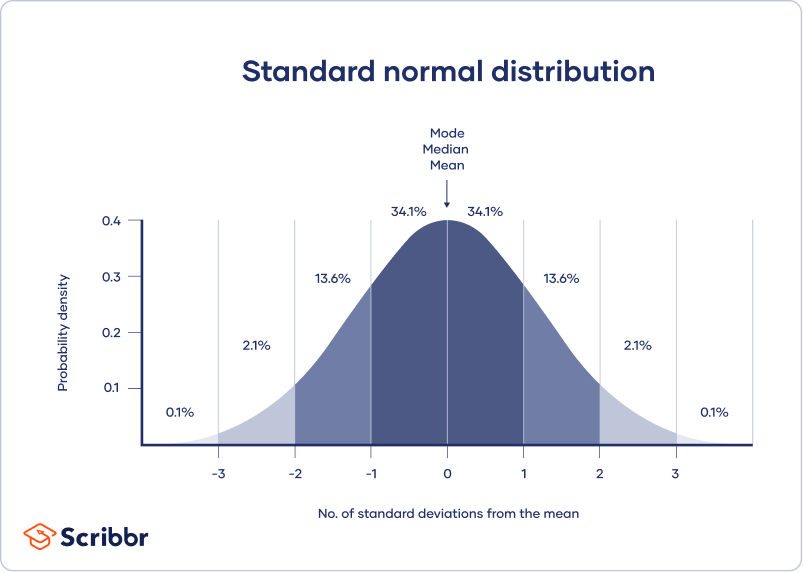
In contrast, a skewed distribution is asymmetric and has more values on one end than the other. The shape of the distribution is important to keep in mind because only some descriptive statistics should be used with skewed distributions.
Extreme outliers can also produce misleading statistics, so you may need a systematic approach to dealing with these values.
Calculate measures of central tendency
Measures of central tendency describe where most of the values in a data set lie. Three main measures of central tendency are often reported:
- Mode: the most popular response or value in the data set.
- Median: the value in the exact middle of the data set when ordered from low to high.
- Mean: the sum of all values divided by the number of values.
However, depending on the shape of the distribution and level of measurement, only one or two of these measures may be appropriate. For example, many demographic characteristics can only be described using the mode or proportions, while a variable like reaction time may not have a mode at all.
Calculate measures of variability
Measures of variability tell you how spread out the values in a data set are. Four main measures of variability are often reported:
- Range: the highest value minus the lowest value of the data set.
- Interquartile range: the range of the middle half of the data set.
- Standard deviation: the average distance between each value in your data set and the mean.
- Variance: the square of the standard deviation.
Once again, the shape of the distribution and level of measurement should guide your choice of variability statistics. The interquartile range is the best measure for skewed distributions, while standard deviation and variance provide the best information for normal distributions.
Using your table, you should check whether the units of the descriptive statistics are comparable for pretest and posttest scores. For example, are the variance levels similar across the groups? Are there any extreme values? If there are, you may need to identify and remove extreme outliers in your data set or transform your data before performing a statistical test.
| Pretest scores | Posttest scores | |
|---|---|---|
| Mean | 68.44 | 75.25 |
| Standard deviation | 9.43 | 9.88 |
| Variance | 88.96 | 97.96 |
| Range | 36.25 | 45.12 |
| N | 30 | |
From this table, we can see that the mean score increased after the meditation exercise, and the variances of the two scores are comparable. Next, we can perform a statistical test to find out if this improvement in test scores is statistically significant in the population.